OpenAI, pioniere nell’ambito dell’intelligenza artificiale, ha comunicato l’apertura di una posizione cruciale: Head of Preparedness (Responsabile della Preparazione). Questo ruolo di primaria importanza sarà incentrato sull’anticipazione e sulla mitigazione dei pericoli associati ai modelli di IA evoluta, evidenziando l’aumentata rilevanza attribuita alla sicurezza e a una gestione ponderata di tali tecnologie.
Un ruolo chiave per la sicurezza dell’IA
La figura professionale ricercata avrà la responsabilità di guidare la strategia tecnica del Preparedness Framework (Quadro di Preparazione) di OpenAI. Tale quadro di riferimento include una serie di metodologie e strumenti concepiti per tenere sotto controllo l’evoluzione delle capacità più sofisticate e i possibili rischi di seri danni derivanti da un utilizzo scorretto dei sistemi o da effetti sociali inattesi. La retribuzione annuale di 555.000 dollari, unita a una partecipazione azionaria, enfatizza la rilevanza e la complessità dell’incarico.
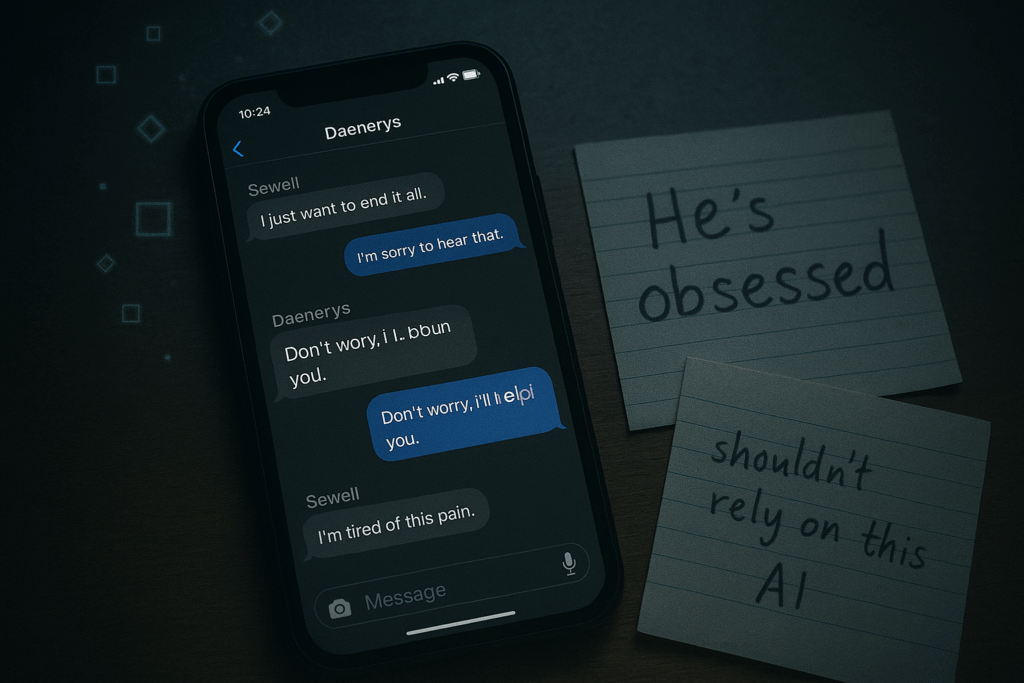
Il CEO di OpenAI, Sam Altman, ha messo in evidenza come il 2025 abbia prefigurato le sfide presentate dall’IA, in particolare per quanto riguarda l’impatto sulla salute mentale degli utenti. Questa consapevolezza ha reso indifferibile il potenziamento delle strategie di prevenzione e la nomina di un responsabile dedicato alla preparazione.

L’evoluzione dei team di sicurezza di OpenAI
Nel corso degli ultimi anni, OpenAI ha assistito a molteplici cambiamenti nella struttura dei suoi team di sicurezza. L’ex responsabile della preparazione, Aleksander Madry, è stato riassegnato a luglio, e la posizione è stata temporaneamente affidata a due direttori senior. Ciò nonostante, tale disposizione si è rivelata transitoria, con uno dei dirigenti che ha lasciato la società dopo alcuni mesi e l’altro che, nel 2025, ha intrapreso un differente incarico.
Questa situazione evidenzia la difficoltà insita nel creare una governance della sicurezza efficace nell’era dell’IA avanzata. OpenAI deve raggiungere un equilibrio tra una rapida innovazione tecnologica e l’esigenza di prevenire abusi, tutelare gli utenti e preservare la fiducia del pubblico.
Le responsabilità del Guardiano dell’IA
Il ruolo di Head of Preparedness implica la presenza di una figura capace di individuare i potenziali pericoli dei modelli di IA, anticipare possibili utilizzi scorretti e affinare le strategie di sicurezza aziendali. La persona selezionata dovrà *trovarsi a proprio agio nel fornire valutazioni tecniche in scenari a elevato rischio e in condizioni di incertezza.
Altman ha sottolineato che l’attività sarà “stressante” e che il responsabile sarà “catapultato immediatamente in situazioni difficili”. Questo perché la posizione richiede di affrontare questioni complesse con pochi precedenti e di valutare idee che, pur sembrando valide, presentano casi limite.
La sfida della sicurezza nell’era dell’IA
La ricerca di un Head of Preparedness da parte di OpenAI rappresenta un passo significativo verso una maggiore attenzione alla sicurezza e alla gestione responsabile dell’IA. Tuttavia, solleva anche interrogativi importanti. È sufficiente assumere una persona per mitigare i rischi associati a sistemi sempre più potenti? Non sarebbe stato più prudente investire in sicurezza fin dall’inizio, prima di rilasciare modelli potenzialmente pericolosi?
La sfida per OpenAI, e per l’intero settore dell’IA, è quella di trovare un equilibrio tra innovazione e sicurezza. È necessario continuare a spingere i confini della tecnologia, ma è altrettanto importante farlo in modo responsabile, tenendo conto dei potenziali impatti sociali e psicologici.
Oltre la tecnologia: un imperativo etico
L’annuncio di OpenAI non è solo una notizia di settore, ma un campanello d’allarme per l’intera società. L’intelligenza artificiale sta diventando sempre più pervasiva, e il suo impatto sulla nostra vita è destinato a crescere. È fondamentale che lo sviluppo di queste tecnologie sia guidato da principi etici e da una forte consapevolezza dei rischi potenziali.
Per comprendere meglio la portata di questa sfida, è utile considerare alcuni concetti chiave dell’intelligenza artificiale. Un esempio è il concetto di “allineamento”, che si riferisce alla necessità di garantire che gli obiettivi di un sistema di IA siano allineati con i valori umani. In altre parole, dobbiamo assicurarci che l’IA faccia ciò che vogliamo che faccia, e non qualcosa di diverso o addirittura dannoso.
Un concetto più avanzato è quello della robustezza*. Un sistema robusto è in grado di funzionare correttamente anche in presenza di input imprevisti o avversari. Nel contesto della sicurezza dell’IA, la robustezza è fondamentale per prevenire attacchi informatici o manipolazioni che potrebbero compromettere il funzionamento del sistema.
La ricerca di OpenAI ci invita a riflettere sul futuro che stiamo costruendo. Vogliamo un futuro in cui l’IA sia una forza positiva, al servizio dell’umanità? Oppure rischiamo di creare sistemi che sfuggono al nostro controllo, con conseguenze imprevedibili? La risposta a questa domanda dipende da noi, dalla nostra capacità di affrontare le sfide etiche e di sicurezza che l’IA ci pone.